前前文介绍了OCR系统的概况,并引出OCR系统中的第二个重要部件为文字识别。
前文详细地介绍了文字检测领域如何利用深度学习建模。
本文则重点介绍文字识别的方法。
[TOC]
Definition
Input
目前做文字识别一般而言指的都是整行识别,因为单字识别依赖字符切分方法,鲁棒性较差,而从深度学习方法出发直接对整行文字提取特征并建立序列模型,可以规避掉字符切分,使得系统更为鲁棒。
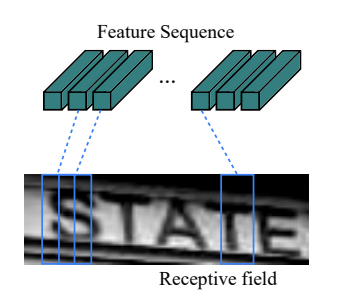
整行识别,输入是矩形图像转化而成的张量形如[N,C,H,W]。刚刚提到,要规避字符切分,则需要把整行识别建模成为序列问题,目前主流的是水平方向建模为序列,输出张量形如[T, C],其中T代表序列长度,与W有某种函数关系,该函数关系取决于特征提取模型。
 ——> “Available”
——> “Available”
Output
输出自然就是识别出来的字符串。由于模型输入输出为向量,故识别模型一般需要带上字符映射表。
Deep Learning
主流的识别模型,可以分为两个派系:
-
以Sliding Window思想为核心的序列建模,代表是CTC类模型,下面简称CTC模型
-
以Seq2Seq思想为核心的序列建模,代表是Seq2Seq+Attention类模型,下面简称Attention模型
CTC
- 代表性论文
[1] Shi, Baoguang, Xiang Bai, and Cong Yao. “An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition.” IEEE transactions on pattern analysis and machine intelligence39.11 (2016): 2298-2304.
华中科技大学白翔老师组的经典论文,借鉴了语音识别里面常用的CTC Loss,结合CNN和RNN做特征提取,把文字整行识别转化为序列问题。
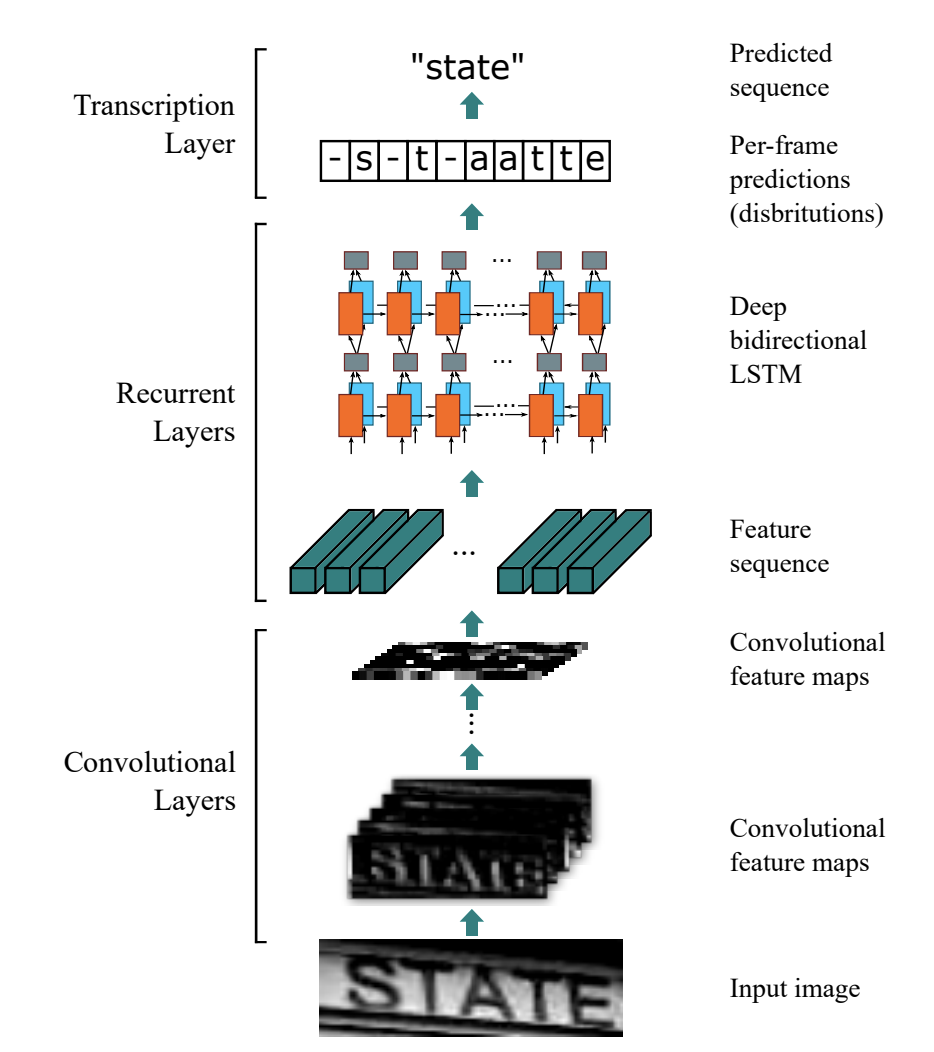
Introduction
-
CNN提取图像特征
原图张量
[N,C,H,W],经过CNN后变成[N,C^,1,W^]。此处的CNN设计其实在实际应用中非常重要。 -
MapToSequence转化为序列特征
通过张量的Permute和Reshape操作,把图像
W^轴转化为序列轴T。该操作可微是CNN和RNN可以joint training的关键。 -
RNN提取序列特征
论文使用LSTM,实际上也可以使用RNN,GRU等,甚至也可以不用…
-
全连接层输出
把特征映射到输出层形成onehot输出
-
训练时使用 CTC Loss,推理时根据CTC做规则合并后处理
CTC全称Connectionist Temporal Classification,见本文最后Reference
关于CTC,有一篇写得非常好的distill.pub的Blog。本文仅讨论个人观点,就不再做详细介绍
- 个人观点
Discussion
CTC模型是典型的Sliding Window思想,每一个时刻对应原图的一个ROI。所以滑动窗类模型的缺点,CTC模型基本都有。
- 首先是滑动窗的大小不好设置,反映到CTC模型的话就是CNN部分不好设计,例如过多的下采样就容易丢失文字。
- 其次是独立性假设使得序列对于前后时刻与当前时刻不存在显式建模,实际上与文字不太相符,因为文字往往是前后语义具备相关性。
Attention
- 代表性论文
[1] Shi, Baoguang, et al. “Aster: An attentional scene text recognizer with flexible rectification.” IEEE transactions on pattern analysis and machine intelligence (2018).
再放一篇白翔老师组的论文。Seq2Seq出自机器翻译领域,后拓展到很多序列建模问题。自然而言,也有研究者把该模型引入到文字整行识别。

Introduction
省略掉上述论文中一些trick,实际上seq2seq可以理解为如下几个部分
-
CNN提取图像特征
同CTC模型
-
MapToSequence转化为序列特征
同CTC模型
-
RNN/GRU/LSTM作为encoder
算子同CTC模型,但是在seq2seq模型里面,这里一般称为encoder部分。
CTC模型取RNN每一个时间步的的输出,因为其满足时间步之间的独立性假设;
Seq2Seq模型取RNN的最后一个时间步特征作为整条的总特征,类似于句向量,
同时也取RNN每一个时间步的的输出作为decoder的输入数据。
-
RNN/GRU/LSTM作为decoder
encoder的总特征作为decoder的初始特征,encoder的每一个时间步特征通过某种机制(直接/某种Attention)转化为decoder每一个时间步的输入。这里就是很多论文发表的关键,因为Attention的玩法相当丰富,有非常非常多的“妖艳贱货”,例如Dot Attention,Perception Attention, Coverage Attention等等,而哪一个Attention更合理,其实没有很好的解释,最终只能是看实验结果。
-
全连接层输出
同CTC模型,但是由于输出的
T维度就是字符数量,不像CTC模型有一大堆blank的输出 -
训练时使用NLL loss或者其他类似的分类Loss,推理时没有特殊后处理
Discussion
Attention模型其实我个人并不觉得是一个适合文字识别的模型:
- encoder得到的总特征,把所有图像特征压缩到一个向量,怎么看怎么觉得奇怪。
- decoder进行过程中,某一个时间步的文字识别错了,有可能会引致下一个时间步文字识别错误,所以在长文本场景往往无法保证识别率。
Reference
[1] Graves, Alex, et al. “Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks.” Proceedings of the 23rd international conference on Machine learning. ACM, 2006.
[2] Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le. “Sequence to sequence learning with neural networks.” Advances in neural information processing systems. 2014.