前文介绍了OCR系统的概况,并引出OCR系统中的第一个重要部件为文字检测。
本文将介绍现代文字检测如何利用深度学习建模。
[TOC]
Definition
Input
输入一般为三通道RGB图像

Output
文字检测系统的输出一般为坐标,由于现代机器学习一般应用强监督手段,所以系统的输出往往也是训练数据的标注真值。由于算法模型或者业务需求的不同,文字的表示有以下几种:
-
N * (word-level/line-level bounding box)
词级别/行级别矩形框 + 字符串,现阶段已经很少有这种表示,因为矩形无法满足文字的多样性。
-
N * (word-level/line-level quadrilateral)
词级别/行级别四边形 + 字符串,是目前的主流,能够表示多种方向多种形状的文字。
-
N * (character-level quadrilateral)
字符级别四边形 + 字符,由于标注成本过高,难有真实场景的标注,一般为合成样本。
Deep Learning
深度学习方法下的检测任务思路,无论是通用物体检测还是文字检测还是什么其他检测,最内核的建模思想都是滑动窗机制下的分类或回归。例如,一张图像1024x1024的输入,设计了一个模型取四倍图,即256x256作为输出,则每一个像素的输出都是该像素映射到原图的感受野区域,经过若干算子做非线性变换后,得到分类概率或者回归值。在这个理解之下,有两种主流的滑动窗衍生的建模思路,分别是设计Anchor针对不同大小不同长宽比的的目标分别进行激活,或者把特征图输出上采样到原图大小,等同于直接每一个输出像素点对应每一个输入像素点,一般认为是分割任务的做法。
Modeling
下面来讨论一下,文字检测在上述几个主流建模思路中的优缺点,纯属个人观点。
Anchor-wise:文字框整体BBox分类+BBox回归
- 代表性论文
[1] Liao, Minghui, Shi, Baoguang, and Bai, Xiang. “TextBoxes++: A Single-Shot Oriented Scene Text Detector.” IEEE Transactions on Image Processing 27.8(2018):3676-3690.
- 优势
-
从通用物体检测迁移而来,能够汲取通用物体检测的一些新思路;
-
由于划分了多个Anchor,等同于模型设计上明确指定某种尺寸的特征就在某个输出通道上激活,这种做法相对而言降低了模型优化的难度,而且BBox回归的难度也相对比较低;
(这一点实际上是Anchor-base类的优势,以下简称为目标明确较易优化)
- 劣势
- Anchor不容易设计,行级别的文字的长边基本无法正确;
- 倾斜文字需要特殊设计Anchor,例如RRPN,但是治标不治本;
- 回归目标的定义由于文字框的多样性,会相对复杂,则回归效果也一般;
Anchor-wise:文字框部件BBox分类+BBox回归
- 代表性论文
[1] Tian, Zhi, et al. “Detecting Text in Natural Image with Connectionist Text Proposal Network.” European Conference on Computer Vision 2016.
[2] Shi, Baoguang, Xiang Bai, and Serge Belongie. “Detecting oriented text in natural images by linking segments.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.
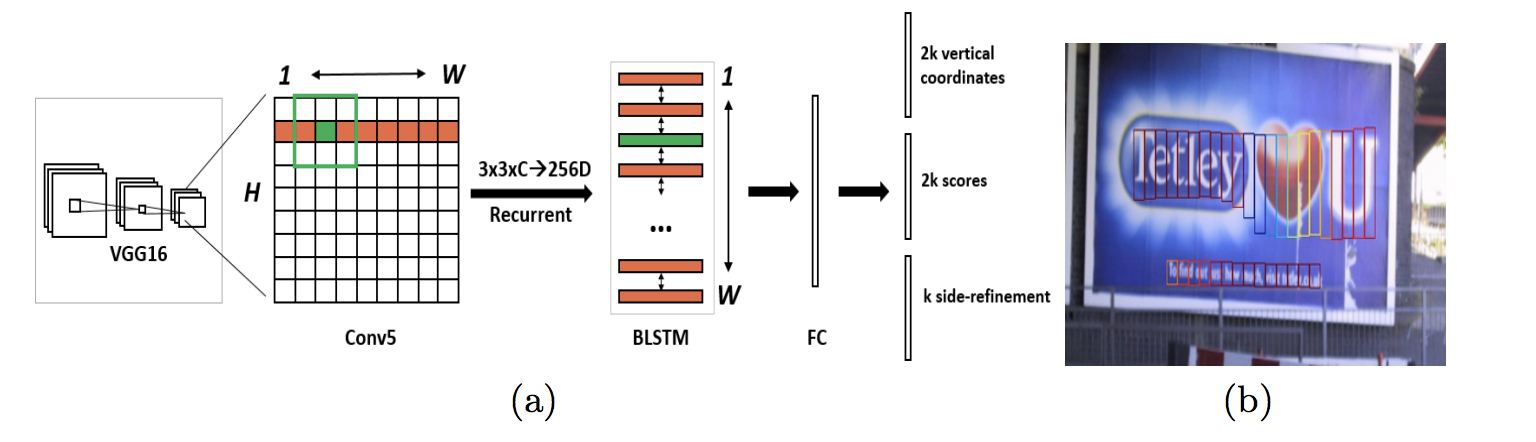
- 优势
- 把文字检测从通用物体检测中脱离处理,引入的一个合理的假设,文字行由文字块组成,大大降低检测的难度
- 同上,一个输出点设计多个Anchor的策略,目标明确较易优化
- 劣势
-
“合久必分,分久必合”的文字框,分成块容易,但是重新合起来该怎么做,就考验算法设计者。CTPN做了一个强假设,文字都是水平方向且大小相近,然后用规则合并;SegLink考虑对每一个文字块做八方向二分类输出,作为是否连接另外一个文字块的依据;但是两者其实在合并中都有很多问题,特别是非水平文本。
(这一点实际上是文字分块建模的劣势,以下简称为文字块合并困难)
-
Anchor一般为矩形,矩形与倾斜文本甚至曲形文本在计算上有一些“不协调”,例如倾斜45度的文字与矩形anchor永远做不到100的IoU,这里的“不协调”影响了LabelAssignment,因为一般是通过设置IoU阈值来进行anchor的正负样本划分,此处的“不协调”让该参数变得非常难以控制。
Pixel-wise:输出点分类+BBox回归
- 代表性论文
[1] Zhou, Xinyu, et al. “EAST: An Efficient and Accurate Scene Text Detector.” IEEE Conference on Computer Vision & Pattern Recognition2017.
- 优势
- 考虑到Anchor设计方面的劣势,直接放弃Anchor机制改为取Pixel输出类别概率。
- 设计简单,所以省去后处理,同等主干网络的话速度快一些。
- 入门容易。
- 劣势
- 每一个输出点都回归该点到文字框边界的距离,这个目标难以优化,考虑到回归任务本身存在一定的误差,即使模型拟合得很好,实际上边界也会有明显误差,长文本尤甚。
- 点分类没有了明确的定义,进行label assignment的时候一般只有“点在框内”和“点在框外”两种,相对于有Anchor稍微难优化一些。
Pixel-wise:输出点分类
- 代表性论文
[1] Deng, Dan, et al. “PixelLink: Detecting Scene Text via Instance Segmentation.” (2018).
[2] Wang, Wenhai, et al. “Shape Robust Text Detection with Progressive Scale Expansion Network.” arXiv preprint arXiv:1903.12473 (2019).
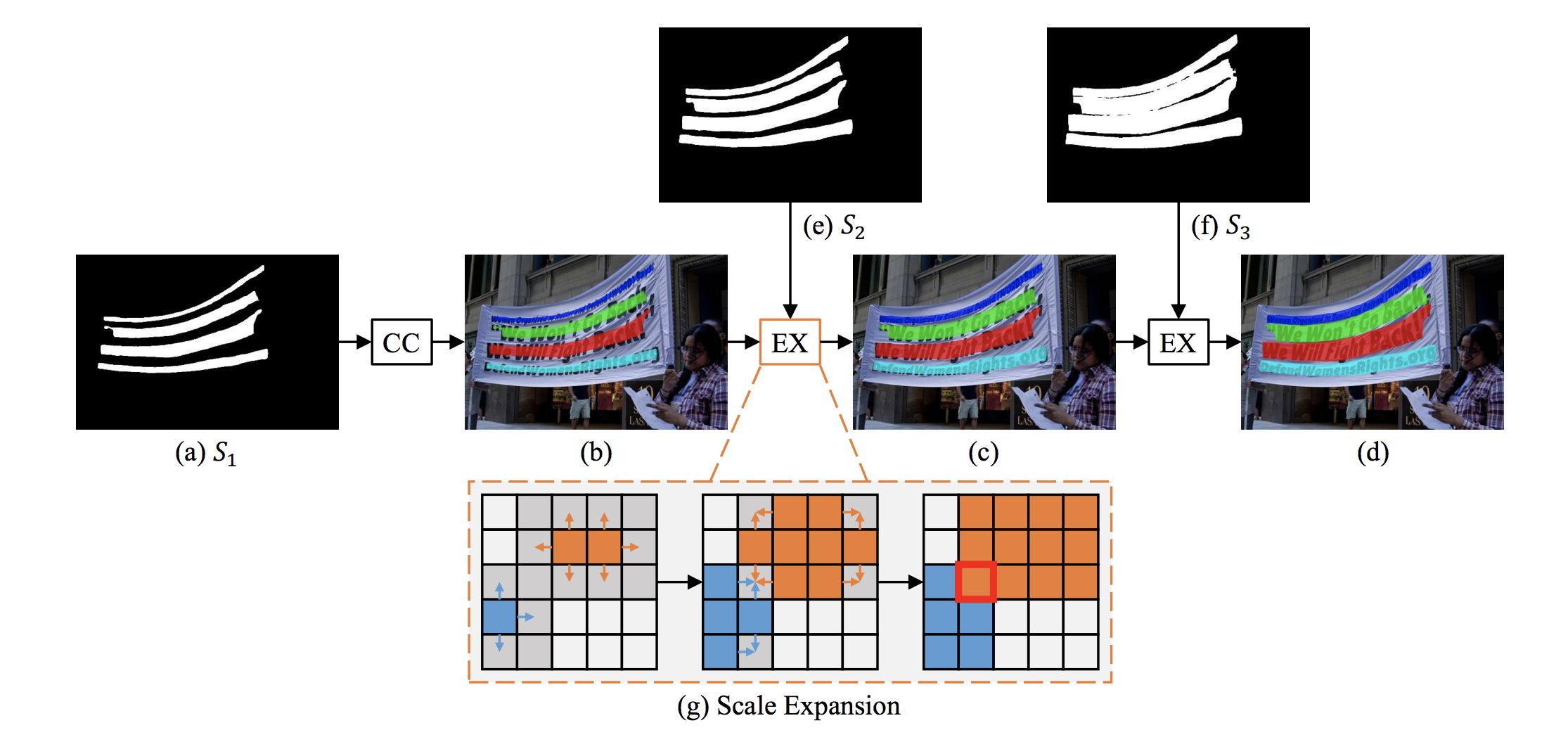
- 优势
- 放弃了BBox的回归,直接输出每一个点的分类概率,转化成二值化图,再转化成文字框。
- 能适应各种形状和形态的文字,曲形,倾斜,任意长度,等等
- 劣势
-
同样地,由于输出点该在什么情况才被激活,没有了明确的定义,进行label assignment的时候一般只有“点在框内”和“点在框外”两种,导致容易出现比较多的False Positive,例如纹理区域。
(这一点是Pixel-wise的通病,以下简称精确率低)
-
后处理复杂,合并困难。PixelLink与SegLink一样要训练八方向(甚至更多方向)的连接二分类器,这个分类器目标不明确,难以拟合。后处理的困难导致容易粘连或者错断。
(这一点也是Pixel-wise的通病,以下简称后处理困难)
-
文字边界不准确,也非常依赖高精准高贴合的文字框标注数据
-
字符间的响应和字符中心的响应不应该等同,这个问题其实来自于词级别或者行级别的标注数据,但是字符级别标注的成本太高,不容易获得。
Pixel-wise:输出点回归
- 代表性论文
[1] Zhu, Yixing, and Du, Jun. “TextMountain: Accurate Scene Text Detection via Instance Segmentation.” (2018).
[2] Xu, Yongchao, et al. “TextField: Learning A Deep Direction Field for Irregular Scene Text Detection.” IEEE Transactions on Image ProcessingPP.99(2018):1-1.
[3] Baek, Youngmin, et al. “Character Region Awareness for Text Detection.” (2019).

- 优势
- 放弃了link,直接输出每一个点的回归值,一般是文字中心或者文本行中心的二维高斯分布。
- 能适应各种形状和形态的文字,曲形,倾斜,任意长度,等等。
- 回归的定义更符合文字的特点,因为文字不是闭合区域,文字边界的响应弱于文字中心应该是比强行二分类好一些。
- 劣势
- 简单字符容易出问题,例如标点符号,数字“1”等等,因为根据定义去训练,响应会比较弱。
-
后处理困难,阈值的设置涉及文字是否粘连或者断开。CRAFT相对而言好一些。
- 字符间的响应和字符中心的响应不应该等同。CRAFT尝试解决这个问题。
Anchor-wise+Pixel-wise
- 代表性论文
[1] Long, Shangbang, et al. “TextSnake: A Flexible Representation for Detecting Text of Arbitrary Shapes.” (2018).
- 优势
- Emmm..设计好了就是两者的优势都有
- 劣势
- Emmm..设计不好即使两者的劣势都有
Post Processing
不同检测模型下,后处理的思路或多或少有差异。由于后处理对检测性能也有非常大的影响,下面讨论一下后处理
NMS
NMS全称Non-Maximun Supression非极大值抑制,此处就不过多减少了,相关资料非常多。NMS的核心假设是,同一个物体只有一个置信度最高的框,所以滤除与该最可信的框有过多重叠的框。一般输出BoundingBox的模型,都需要NMS作为后处理。
可以写CUDA实现
MinAreaRect
最小外接矩形一般用于二值化特征图直接输出后,转化成为矩形输出的时候使用。该方案相对而言比较粗糙,很容易出现粘连的情况。
可以调用OpenCV函数。
Watershed
分水岭算法Watershed是近期比较流行的一个处理二值化特征图的方法,相比起最小外接矩形,分水岭对于粘连问题有较好的表现。对于文字而言,最好是通过合理的建模,得到比较可靠的文字“骨干”(Skeleton),然后从“骨干”出发,用Watershed找到每一个文字框。
可以调用OpenCV函数。此处是watershed的sample code
Reference
[1] Neubeck, Alexander, and Luc Van Gool. “Efficient non-maximum suppression.” 18th International Conference on Pattern Recognition (ICPR’06). Vol. 3. IEEE, 2006.